Healthcare
How a Regional 3PL Reduced Shipment Exceptions and Manual Firefighting with an AI Exception Management System
A mid-sized third-party logistics provider managing domestic freight across truckload, LTL, and time-sensitive retail shipments.
The Challenge
The client’s operations team was spending too much of the day reacting to problems instead of
preventing them.
Most shipments moved as expected, but the business was getting buried in exceptions:
Missed pickup windows
Delayed trucks
Inventory shortfalls
Wrong or missing paperwork
Last-minute customer changes
Receiver delays
Appointment issues
Incomplete status visibility across carriers and internal teams
The problem was not a single broken workflow. It was the sheer volume of small disruptions that required constant manual follow-up.
Dispatchers and customer operations staff were checking multiple systems, reading emails, calling carriers, updating customers, and deciding what to escalate — often under time pressure
and with incomplete information.
This maps directly to one of the biggest logistics pain points in your research: operations teams spend significant time triaging exceptions, identifying root causes, deciding on next actions, and coordinating updates across teams and systems.
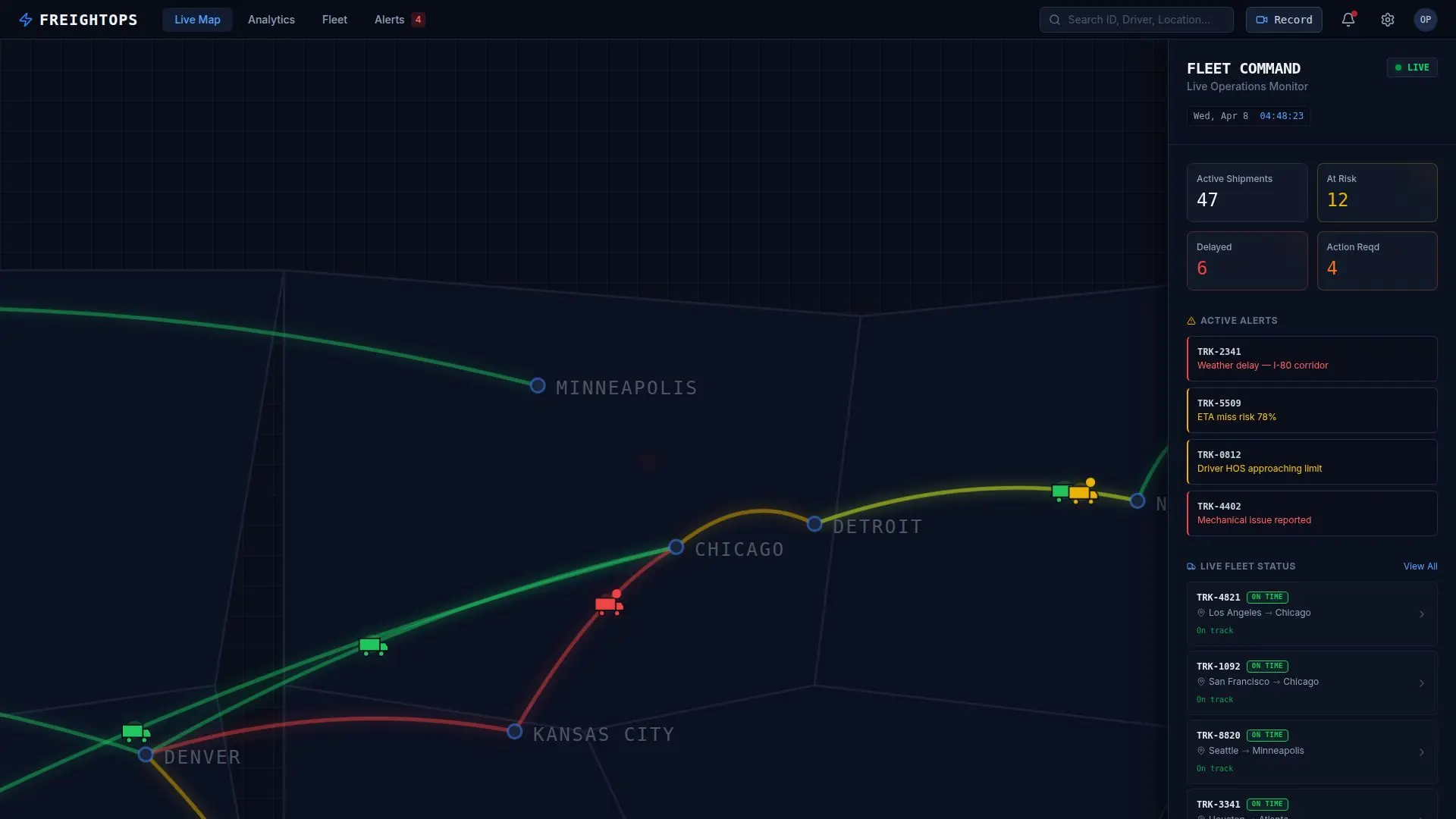
The Business Impact
As shipment volume increased, the client’s existing operating model started to break down. Their team was facing:
Too much manual exception handling
Delayed responses to service issues
Inconsistent escalation decisions
Too much manual exception handling
Limited visibility into which issues actually mattered most
Growing pressure to improve service without increasing headcount
Leadership did not want to solve the problem by simply hiring more coordinators. They needed a way to make the operation more proactive, more consistent, and less dependent on inboxes, spreadsheets, and individual heroics.
Our Approach
We did not begin with a generic AI assistant. We started by analyzing how exceptions moved through the business. That included:
Interviews with dispatch, customer operations, and leadership
Mapping the flow from shipment creation through delivery
Identifying where exceptions first became visible
Reviewing how the team classified severity and ownership
Analyzing how updates were communicated internally and externally
Identifying which actions were repetitive and which truly required human judgment
What we found was that the team was not failing because of a lack of effort.
They were failing because exception handling depended on too much human glue work:
- Checking multiple systems
- Interpreting fragmented updates
- Deciding who owned the problem
- Manually triggering next steps
- Keeping customers informed
The real problem was coordination at scale. That is exactly the kind of logistics problem where AI creates value — not through creativity, but through better orchestration, faster decisions, and earlier action
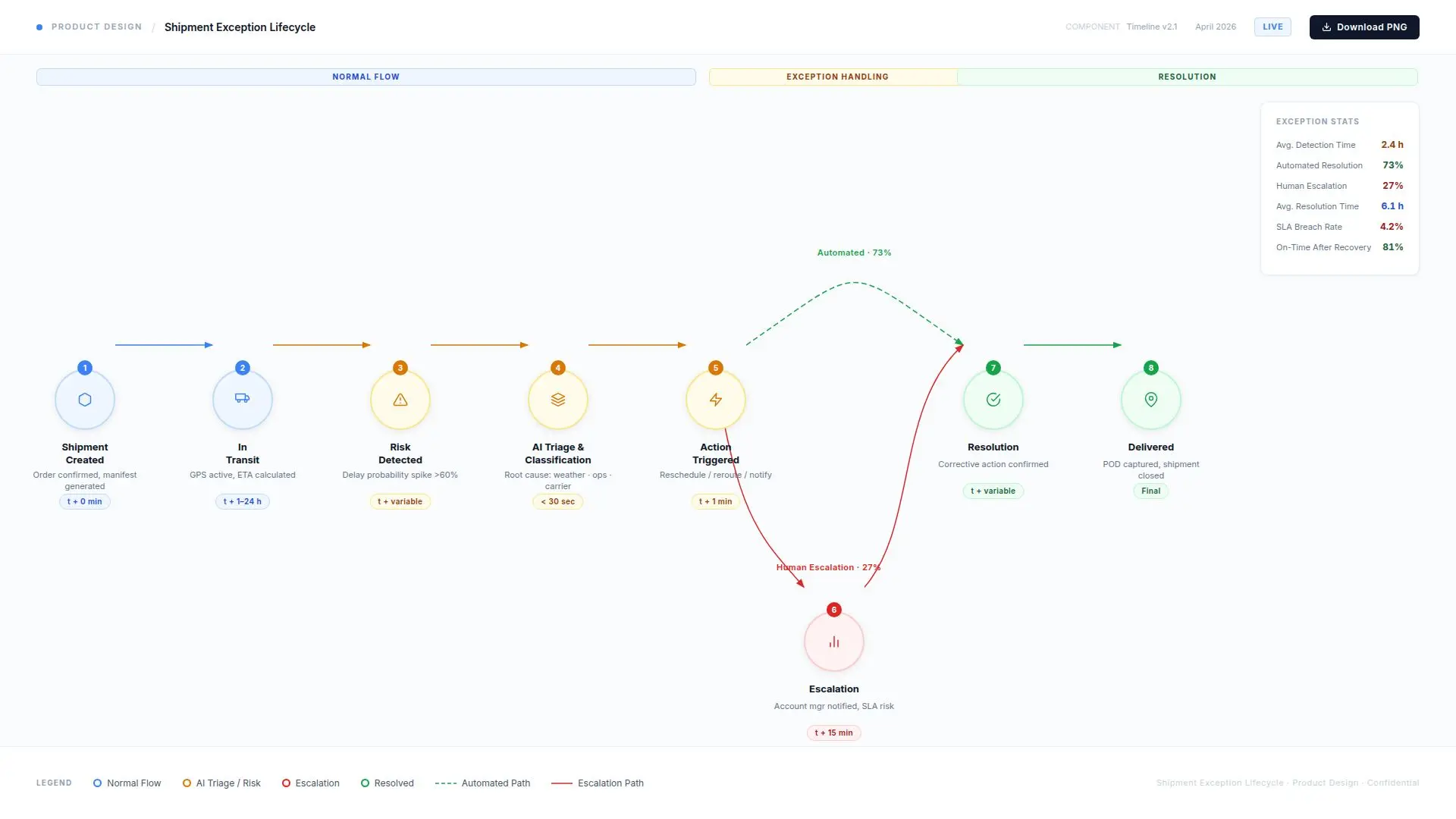
The Solution
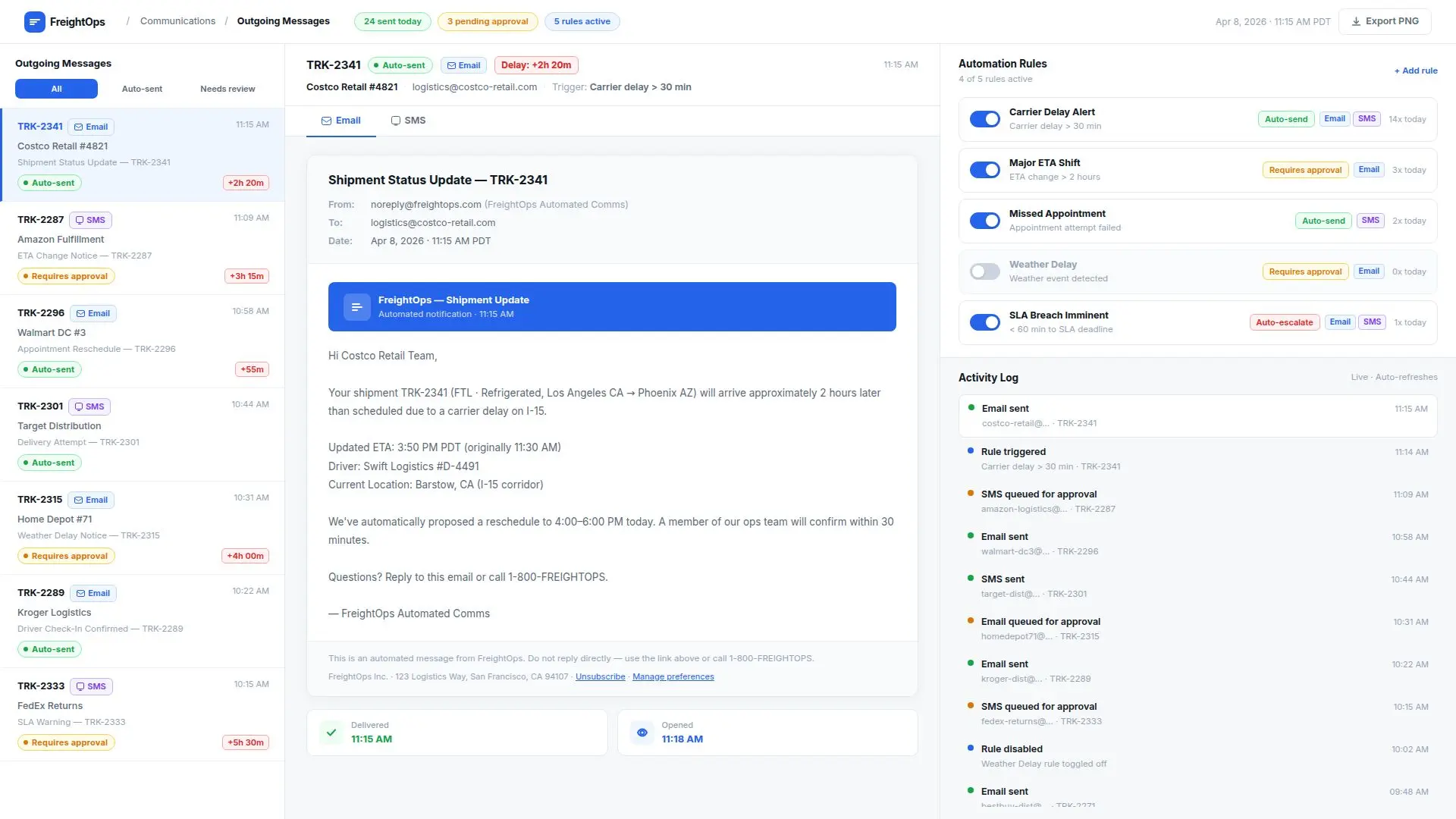
We designed and implemented an AI Exception Management and Response System that monitored shipment workflows, identified likely service risks, and triggered the right next steps before issues escalated.
The system was designed to:
Monitor orders, shipments, appointments, carrier updates, and operational events
Detect likely delays, missed commitments, and service risks
Classify severity based on customer, timing, and shipment context
Recommend or trigger next-best actions
Route exceptions to the right internal owner when human intervention was needed
Send proactive updates to customers for routine delay scenarios
Maintain a structured record of what happened, what action was taken, and why
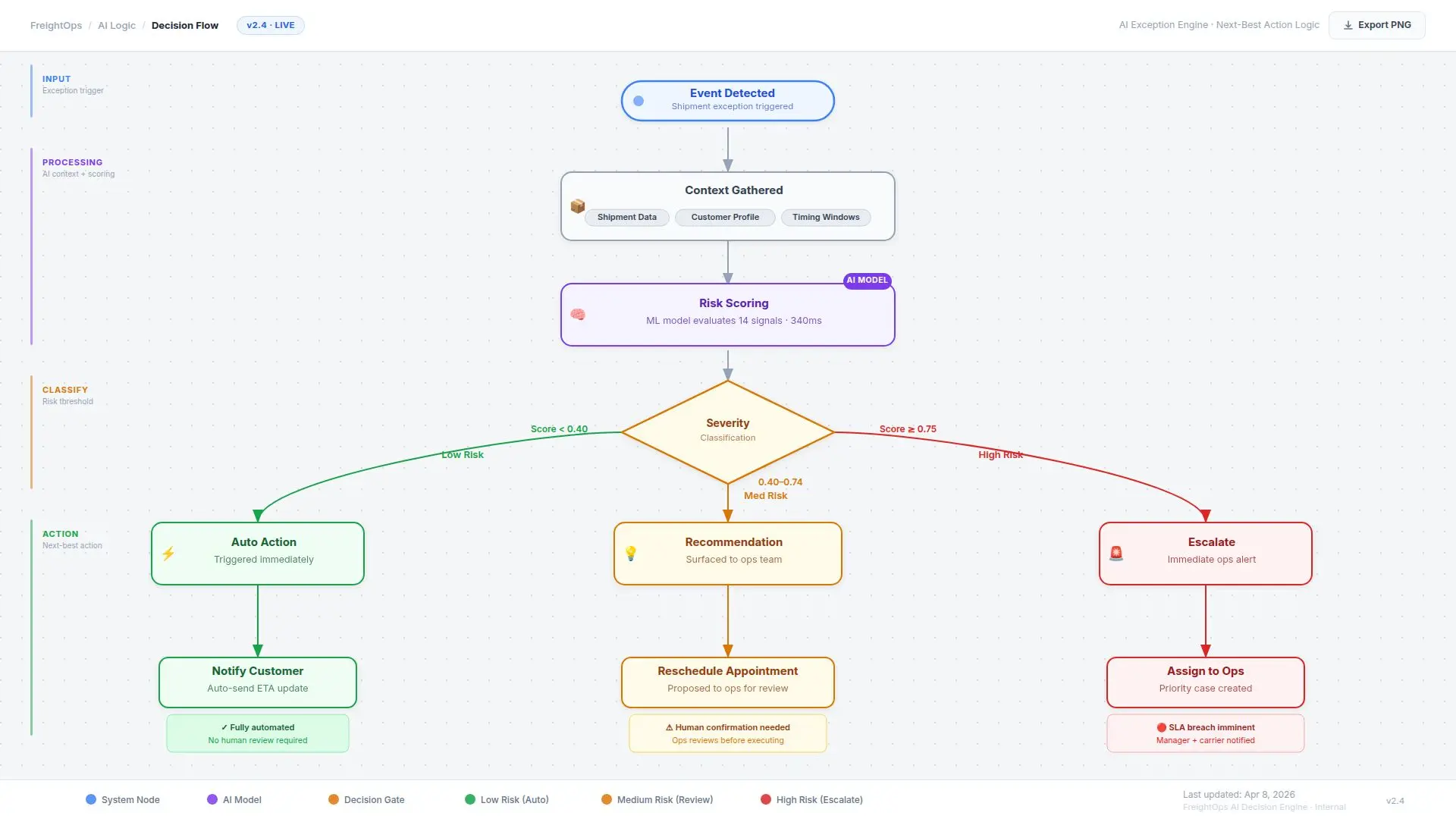
What the System Actually Did
When a shipment showed signs of risk, the system did more than raise a generic alert. It gathered context, evaluated the situation, and generated the next action.
For example:
- If a shipment was likely to miss its appointment window, the system checked shipment priority, customer commitments, and available recovery options
- If the issue was low-risk and routable, it triggered a reschedule or draft update automatically
- If information was missing, it initiated the right follow-up with the carrier or internal team
- If the situation involved a high-value customer or a higher-risk service failure, it escalated the case to operations with a structured summary and recommended next step
- Once action was taken, the system updated the case state and reduced repeated status chasing across teams
Instead of forcing staff to investigate every minor issue from scratch, the system handled the first layer of detection, triage, and workflow coordination.
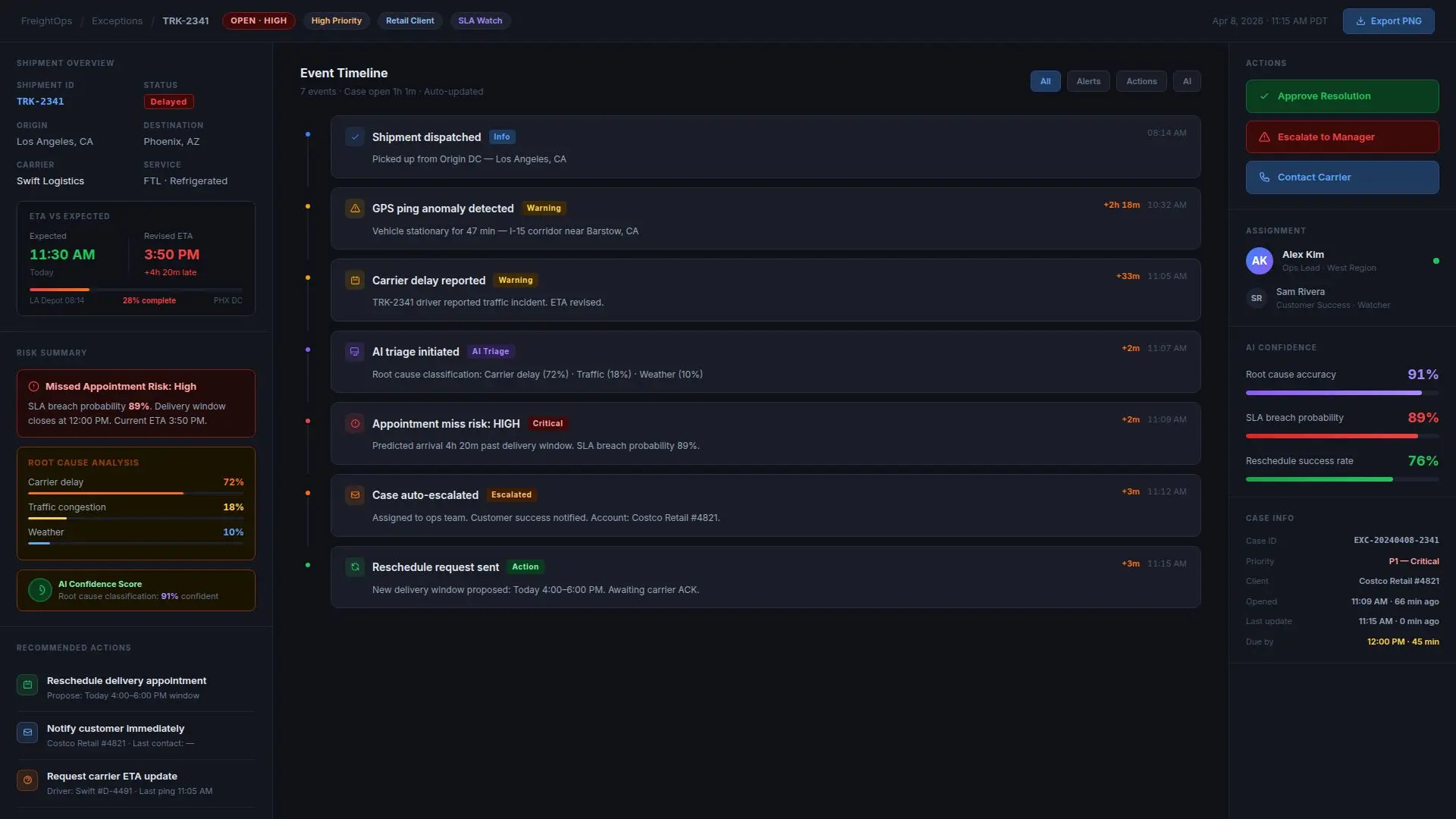
What Product Management & UX Work
Instead of forcing staff to investigate every minor issue from scratch, the system handled the first layer of detection, triage, and workflow coordination.
Which exceptions mattered most
How severity should be ranked
What actions could be automated safely
When humans needed to remain in control
How dispatch and customer operations teams would see and interact with exception queues
What customer communications could be standardized
We also designed:
- An exception dashboard
- Internal case views with root-cause and action summaries
- Escalation states
- Communication templates for customer-facing updates
- Reporting views for aging issues, repeat failure patterns, and resolution performance
This mattered because the goal was not just to add alerts.
It was to reduce cognitive overload and help teams act faster with better information.
Security & Controls
Because the system touched customer data, carrier updates, shipment records, and internal operating logic, it was built with clear operational controls.
That included:
Role-based access by function
Approval thresholds for customer-facing actions in higher-risk cases
Logging of every alert, action, escalation, and override
Clear boundaries between automated handling and human escalation
Monitoring for routing quality and false positives
The client needed the system to be useful, predictable, and accountable.
Implementation
The engagement was delivered in phases.
Phase
01
Discovery and workflow analysis
We interviewed teams, mapped the current exception lifecycle, reviewed system inputs, and identified the highest-volume disruption types.
Phase
02
Product and workflow design
We designed the exception classification model, escalation rules, next-best-action logic, and user workflows for dispatch and customer operations.
Phase
03
System build and integration
We built the orchestration layer, connected it to the client’s shipment and communication systems, and implemented event monitoring, case routing, and action logic.
Phase
04
Launch and operational rollout
We launched with a limited set of exception categories first, trained the ops team, refined escalation thresholds, and improved communication logic based on real usage.
Phase
05
Monitoring and optimization
After launch, we tracked detection quality, time-to-action, exception aging, and manual handling rates to improve performance over time.
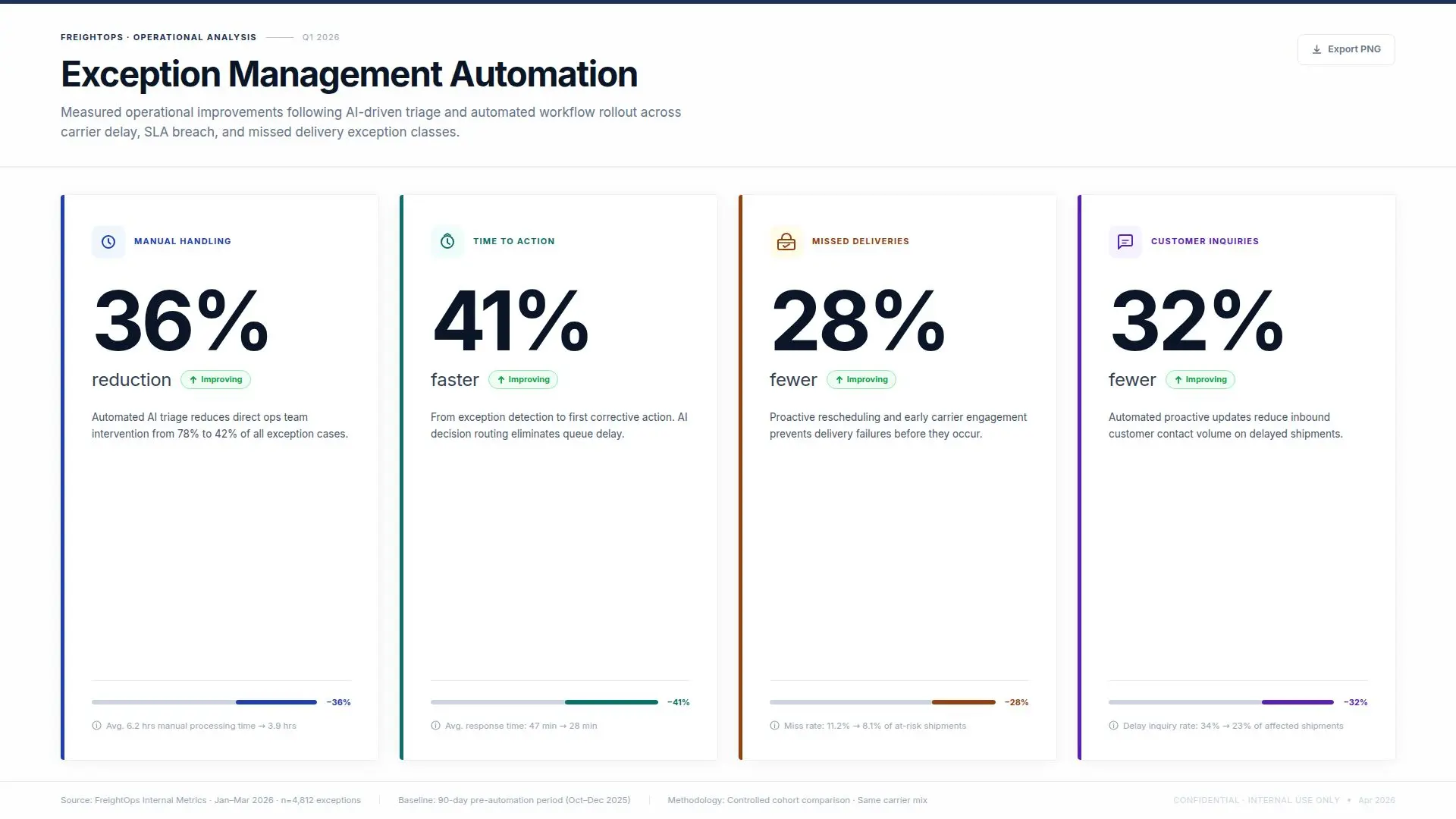
Results
● improved consistency in escalation and response handling across operations teams
Just as importantly, dispatchers reported spending less time hunting for information and more time handling the cases that genuinely required judgment.
Why It Worked
This project worked because it focused on one of the most painful realities in logistics: most operational drag comes from constant small disruptions, not just major failures. The client did not need another dashboard full of alerts. They needed a system that could:
- Detect what mattered
- Decide what to do next
- Trigger action across the workflow
- Keep humans focused on the exceptions that truly needed them
That is exactly why exception management is one of the strongest AI use cases in logistics. It sits at the intersection of visibility, coordination, service, and cost.
That is exactly why exception management is one of the strongest AI use cases in logistics. It sits at the intersection of visibility, coordination, service, and cost.
Client Outcome
The client did not just improve exception handling. They gained: